TimescaleDB
Sun 06 August 2017 • Tags: postgresqlThis article is about TimescaleDB, a postgreSQL extension, specialized in storing Time Series data. The purpose is being able to easily manage data coming almost sorted on a time dimension. Log or audit events for instance.
Why TimescaleDB ?
PostgreSQL 10 introduces a real partitioning scheme. Before that, users had to resort to inheritance, writing triggers themselves on a parent table, and it was quite slow and hackish.
There are still quite a few limitations in PostgreSQL 10's partitioning:
- No row movement between partitions (if you change the value of the partitioned column)
- No dynamic pruning of partitions (you have to specify criterion statically in the SQL query for the optimizer to consider not accessing a partition)
- And most importantly in our use case, partitions cannot be created automatically. In order to insert into a partition, the partition must already have been created, or you'll get an error
In the specific use case of time series, timescaledb improves this.
It features:
- Automatic creation of new partitions when required (one tries to insert data in a not previously seen time range)
- Hash partitioning for additional dimensions if required (this will be in PostgreSQL 11)
- Fast dispatch into the partitions through an executor hook (PostgreSQL 10 has it also for partitioning, but this is a big step forward from PostgreSQL 9.6)
- Some improvements in the executor, mostly for sorting/getting first rows on the time column
The main benefits will be:
- IF the current partition fits in cache (that should be your target), you'll have much faster inserts as indexes will be in memory and so it will be much faster to insert data in them at the right place, do page splits, and all these modifications will only go to disk once every checkpoint
- You'll have a much easier time when deleting old data. It's only a matter of dropping partitions, which are only tables…
Installation
It's a PostgreSQL extension. If it is packaged for your distribution, use the package. Else, just compile it.:
git clone git@github.com:timescale/timescaledb.git cd timescaledb # Bootstrap the build system ./bootstrap # To build the extension cd build && make # To install make install
Then, put timescaledb in shared_preload_libraries in postgresql.conf, and:
CREATE EXTENSION timescaledb
in the database where you want to use timescaledb.
Depending on your context, you'll probably have one big table you want to partition, and a few others.
My tests were done on a single table containing a few meta-data fields (insertion timestamp, user id…) and a JSON containing the raw data to store, around 2kB.
Let's say you just created an events table. To transform it into an hypertable (it just means the table is partitionned),
SELECT create_hypertable('public.events', 'created_at', chunk_time_interval => 604800000000, create_default_indexes=>FALSE);
chunk_time_interval is the size of each partition (in microseconds, here a week, by default a month).
For more details, see <http://docs.timescale.com/latest/api#create_hypertable>
Internals
We won't go into too much detail here. The important things to know are:
All of timescale's metadata is stored in the _timescaledb_catalog (list of the chunks and characteristics of the hypertable…), chunks (partitions) are hidden in _timescaledb_internal.
TimescaleDB uses executor hooks to intercept queries and redirect them to the correct chunk (and create chunks when missing), to get fast inserts. It also uses planner hooks to take advantage of the specific nature of the inserted data (sorted by time…).
From the user's point of view, there is no difference in using timescaleDB or a pure PostgreSQL.
For a DBA, it's a bit more complicated. Almost everything will work unchanged, except pg_dump, which will be a bit problematic. TimescaleDB provides scripts and functions to dump and restore the database, and these should be used instead: pg_dump won't dump an hypertable correctly as it has no knowledge of it's real structure and will restore the hypertable, the chunks, their indexes in the wrong order. You'll end up with duplicate indexes or errors. So use ts_dump.sh and ts_restore.sh if you need to export and import.
Testing/benchmarking
Our test server was an EC2 Amazon i3.8xlarge (https://www.ec2instances.info), with 4 NVMe SSD (configured as RAID 0), 256GB of RAM, 32 vCPU.
The PostgreSQL instance was configured like this (quite agressive):
shared_buffers = 4096MB # min 128kB work_mem = 128MB # min 64kB maintenance_work_mem = 1GB # min 1MB vacuum_cost_limit = 2000 # 1-10000 credits bgwriter_lru_maxpages = 10000 # 0-1000 max buffers written/round bgwriter_flush_after = 0 # MC # measured in pages, 0 disables effective_io_concurrency = 4 # 1-1000; 0 disables prefetching wal_compression = on # enable compression of full-page writes wal_log_hints = on # also do full page writes of non-critical updates max_wal_size = 8GB effective_cache_size = 128GB log_checkpoints = on autovacuum_vacuum_cost_delay = 1ms # default vacuum cost delay for
Huge pages were activated and in use for the shared_buffers.
Our test data's event table was very similar to this:
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+------------------------------------
id | bigint | | not null | nextval('events_id_seq'::regclass)
event_id | uuid | | not null |
event_type | text | | not null |
created_at | timestamp with time zone | | not null |
data | jsonb | | not null |
Indexes:
"events_pkey" PRIMARY KEY, btree (id)
"events_id" btree (event_id)
"events_categories" gin ((data -> 'categories_ids'::text) jsonb_path_ops)
"events_created_at" btree (created_at)
"events_type" btree (event_type)
The inserted json was ~2kB.
For insertion, a Perl script was written to insert records as fast as possible, using 16 sessions. It generated different uuids, almost all increasing created_at's timestamp (with a random variation to be closer to reality), and edited parts of the JSON such as the categories to have a random list of categories. For our use case, we cannot lose one record, so each insert was in its own transaction (which is bad).
In all the following benchmarks, IO was not a limitation, because of the very fast storage. IO use was much lower with TimescaleDB though.
First thing to note:
SELECT create_hypertable('events', 'created_at',chunk_time_interval => interval '1 week');
ERROR: Cannot create a unique index without the column: created_at (used in partitioning)
It's quite logical: there is no way we can guarantee unicity of this column across all chunks, which are in fact separate tables. So the primary key was transformed into a simple index.
The same benchmark was performed, without timescale and with it. Here is the graph:
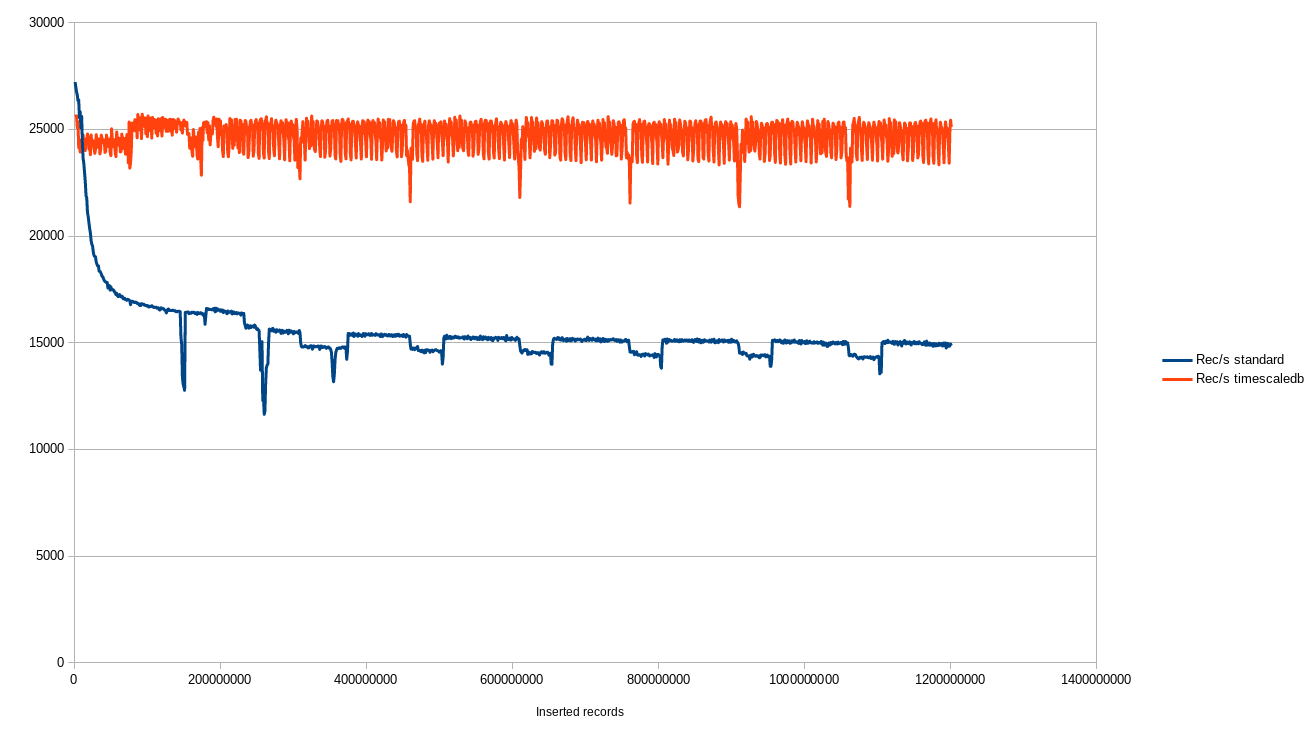
There are quite a few things to note:
- This seems to contradict this benchmark: https://blog.timescale.com/timescaledb-vs-6a696248104e, but it's not.
Test cases were very different: we are inserting quite big records, had a large amount of memory (256GB), and very fast storage (much faster than TimescaleDB's storage). Indexes were small compared to the total size, and never out of the cache in our test setup. So we don't have the steep degradation… we still have more cost to maintain indexes, but the indexes' cost seems to be grow logarithmically, as it should be when cache problems are not involved. At the end of this benchmark (1 terabyte inserted), intermediary pages in the indexes weighted for around 0,3% of their total size.
- During PostgreSQL's inserts, we saw (very raw estimates) between 250MB/s and 500MB/s of writes. With TimescaleDB, between 125MB/s and 250MB/s (depending on whether the database was performing a checkpoint or not). As PostgreSQL was inserting less records with more writes, TimescaleDB was more efficient. It probably was down to more pressure on the shared_buffers, as the database was much bigger. So we still saw the same effect as in TimescaleDB's benchmark, except that the hardware was able to cope.
Input/Output per second was on the same scale: 40000 writes per second with native PostgreSQL, 10000 per second with TimescaleDB.
- There are plenty other advantages with TimescaleDB (as with partitioning in general)
Conclusion
For our use case, expected load is much lower. This benchmark was mostly carried out of curiosity, to see what the limit was with both solutions. Performance wise, both solutions would be perfectly OK for our use case.
What would make us chose TimescaleDB are mostly the following points:
- Insert speed is (almost) constant.
- Insert speed is higher.
- Expiring old data is extremely simple,
Here's an example
timescaledb=# select drop_chunks(interval '2 years'); drop_chunks -------------+ (1 row) Time: 3.712 ms timescaledb=# rollback ; ROLLBACK Time: 0.206 ms
- It's nice to be lazy and not manage partitions ourselves.
What would prevent us from using it (or at least give us second thoughts):
- It's a moving target: for now, new versions come out very fast. That's normal, it's very new. It's worth noting that TimescaleDB was rock stable during the tests.
- It's not packaged for debian (porting packages from ubuntu is easy enough though).
- You have to be careful with dumping/restoring, as you cannot use the standard procedures. It means that this particular server may have different procedures from the rest of your PostgreSQL servers.