How we treat inbound emails right with Amazon Web Service
Tue 25 September 2018 • Tags: Amazon JAVAAn email invasion
At PeopleDoc, we are facing an amazing growth in our application's usage. More and more companies use dematerialized documents and they want to integrate them as easily as possible into our application.
That's why we provide them with a feature where they can add documents into PeopleDoc through emails.
But as we grow, we receive more and more emails to analyze, parse and store. Our previous workflow was good until some point that we recently reached. We needed a more reliable, fault resilient and scalable solution.
This article is about how we did it from a functional point of view. Another article with technical details might see the light in the future.
Our current architecture
At People Doc, we try to divide our products into microservices. We have a microservice which handle the storage of documents, another for converting docx files to PDF, one for sending emails and so on.
We also have a micro service which is responsible for handling incoming emails, which is the feature we will be discussing about in this article. The advantage of having a microservice dedicated to this feature is that we can change it without impacting all other applications (obviously).
The user story is as follow:
As a user of PeopleDoc,
I want to easily send documents on PeopleDoc platform
So that using PeopleDoc day to day is a delight ;D
And here is an acceptance test that goes with it:
Given an email address associated with a PeopleDoc user's account
When I send an email with an attachment to this address
Then I can see the email in the Inbox of the user with the attachment.
One of the use case is to be able to scan document and send them directly on PeopleDoc (as many enterprise scanners have a functionality to send scanned documents through email). Once they are sent and received by our service, they appear in PeopleDoc interface as a new inbox item.
Specifications
We had a few specifications before starting this project:
- We don't want to handle our own SMTP server. It's painful and quite complicated to set up and maintain.
- The application must be fault resilient. As a SaaS company, we might face downtimes on some of our applications. Nevertheless, we must be resilient and impact as little as possible our clients.
- The application must be scalable. As our client's number grow, we need to build an application which will handle more and more incoming emails every day.
- Data must be handled in Europe. Our product works all around the world. However, laws in Europe are different from other continents. Our clients want all their data to be handled and stored in EU and that's what is written in our contracts.
The Workflow
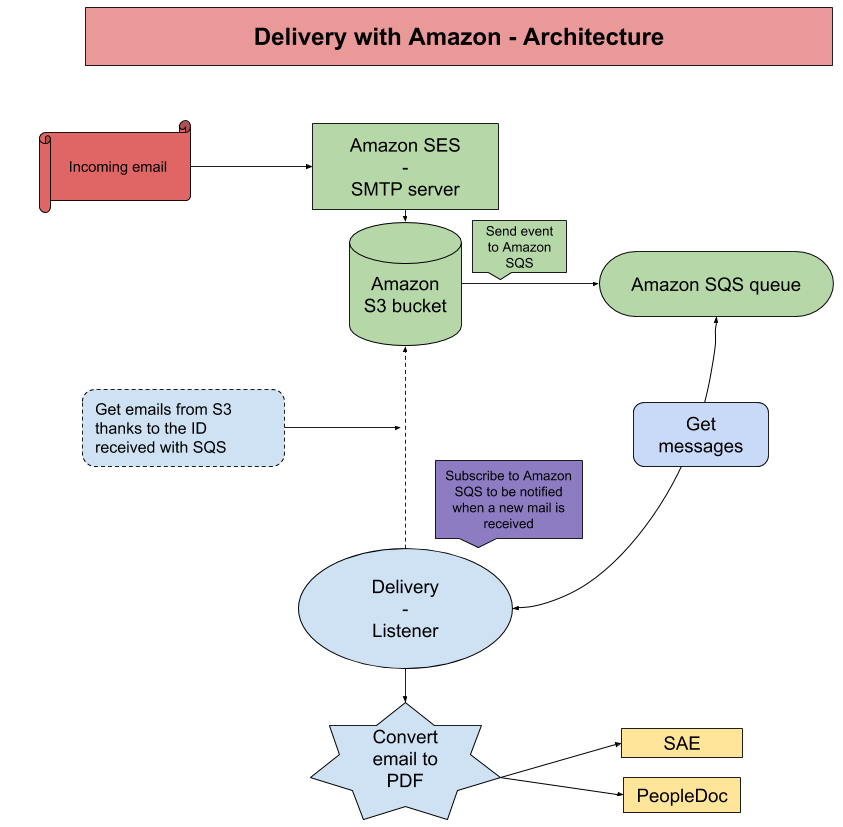
We had identified that Amazon could be of a great help with one of its services: Amazon Simple Email Service (SES). They offer to handle all the SMTP server and allow us to write custom rules for incoming emails. All we have to do is to configure our DNS to redirect all incoming emails arriving on our domain name to the Amazon SMTP server located in Dublin.
Once our emails are received, we encrypt them and store them in Amazon Simple Storage Service (S3). Here again, Amazon allow us to write custom rules when an object is stored in S3. So what we did was to send an event on a queue, containing the ID of the email.
This queue is handled by another Amazon service; Simple Queue Service (SQS). This is a queue on which an application can register to be notified when a new message is posted on it. So we plugged our application to this queue and we are now notified each time a new incoming email is received!
When our application is notified, it gets the ID of the email from the SQS message, downloads the email from S3, decrypts it, retrieves its attachments, upload them on our secure storage (which is called SAE, for Système d'Archivage Électronique) and create a new message in the user's inbox in People Doc.
Here is what it looks like on a diagram:
Completely scalable
Building this application gives us quite some advantages.
First of all, today, we have a stateless application, and that means a lot! Retrieving and parsing emails doesn't require to store any data. So we can have multiple instances of our application doing the work at the same time, distributing the load of these tasks between each application. Whether these instances are on the same server or not doesn't change a thing!
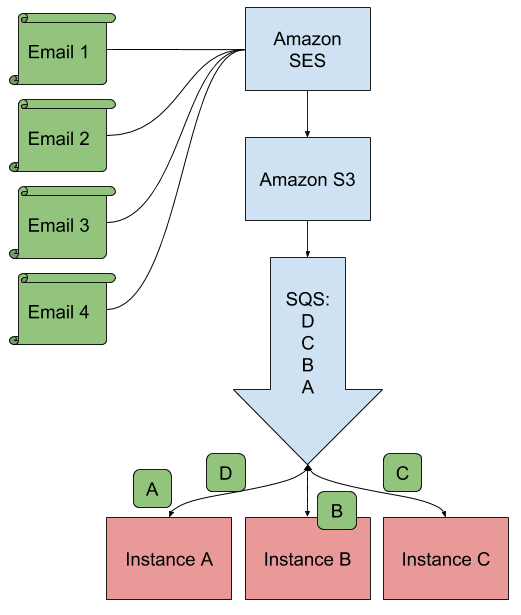
When an instance reads an event from SQS, this event becomes invisible for other instances. It processes the event, get the emails, parse it and, eventually, if all went well, it acknowledges the event so that it is removed from the queue.
Fault resilient
However, if the event has not been acknowledge for a certain amount of time since it has been retrieved by an instance, it automatically reappears in the queue. This scenario is quite useful when an instance starts processing an event and then crashes in the middle of the process (network failure, server issue…). In this case, the event will automatically reaper and another instance will process it.
Downtimes
A good point also is that if our application is down for some reason, nothing is lost. We can afford downtime and that's quite a relief!
When the application is down, all emails are still stored on S3 and events are piling up in SQS. Once the application is back online, it simply retrieves the events one by one and starts processing the email again.
SQS events can stay in the queue for a maximum of 14 days. Hopefully, our application will never be down so long…
Encryption
When emails are received by SES, they are encrypted by SES before being stored on S3. When we retrieve them with our application, they are still encrypted. We are using a client-side encryption so they are never unencrypted when they go through the network.
What's next?
We encountered a few pain points while developing this solution (like setting up the encryption policy or getting information about what emails look like when they are stored) but, despite that, setting up this whole process was quite straightforward. Amazon provides open source SDK that you can find on Github and creating new services on their administration console is intuitive.
However, everything is not done yet. We need for instance a way to monitor the number of emails going through this process and more precisely the number of emails which are on error. For those on error, we need to be able to replay them again, in case the error was due to an external factor at the time the email was first processed.
So even if the main functionality is done, there is still room for improvements!